Viterbi Algorithm and Its Use for Predicting States Using Emoji Observations
See the implementation of the Viterbi algorithm in Python
Sarcasm
Until I started using social media heavily, I did not know smile emoticon can be sarcastic. I, myself, have used the smile emoticon to express the “fine!” expression many times. I have seen others use them a lot too to express similar expressions. Observations and states are different. What we see or observe, might not give an actual representation of the state. As the quote “an elephant has one teeth to show and other teeth to chew” says, the observations and states might sometimes be in contrast to each other. Sarcasm is real!
Binita and Emojis
Binita is my wife. I have been asking her to select an emoticon daily on how she feels on a particular day. I have given her three choices — laugh, smile, and cry, and she selects an emoticon daily. My intention in asking her to choose an emoticon daily is to know how she feels each day. I assume she can either feel happy or sad.
So, the observations I can make are laugh, smile, and cry, and the states are happy and sad. Observations are visible on me, but the states are not. The states are hidden from me.
I want to know her state daily, and so, I am modeling this scenario as a hidden Markov model and I am using the Viterbi algorithm to find the states.
Code and Modeling
Let’s put the things we know so far in various Python data structures.
states = (‘happy’, ‘sad’)
Now, I assume the state of being happy/sad satisfies Markov property. So, her state tomorrow depends only on her state today, and not on her state of yesterday and/or before. In addition, I am also assuming the transition probabilities and emission probabilities. Transition probabilities give probabilities of transition between different states. And, emission probabilities give probabilities of observations given the states.
The graphical representation of the hidden Markov model is shown below:
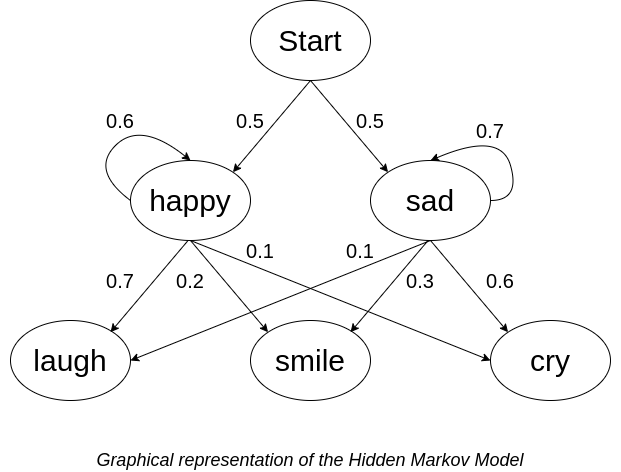
I have asked her for five days in a row about her feeling. Today I want to use the Viterbi algorithm to know her states from the observations. My note says her feelings during the last five days are:
observations = (‘smile’, ‘laugh’, ‘smile’, ‘cry’, ‘laugh’)
Now, my task is to find out the states from the observations and probabilities.
First day
Let’s look at the first day. The first day, she sent me “smile” emoji. She could smile either being happy or being sad. The “smile” emoji can come two ways. Either she is happy, and she expressed her state through the “smile” emoji. Or she is being sarcastic and sending me “smile” emoji.
So, the probability that she is happy on the first day is the probability that she is not being sarcastic on the first day i.e she smiled and she is happy on the first day. Similarly, the probability that she is sad on the first day is the probability that she is being sarcastic on the first day i.e she smiled though she is sad on the first day.
So, probability of she being happy = probability of her smiling and being happy
= probability of she being happy * probability of she smiling after being happy
= 0.5 * 0.2
= 0.1
Similarly,
probability of she being sad = probability of her smiling and being sad
= probability of she being sad * probability of she smiling after being sad
= 0.5 * 0.3
= 0.15
Interesting! According to the probabilities we assumed, she is sad on the first day. God, I should have calculated the probability on that day only. I could have tried to change her mood :|
Let’s implement the first-day condition in the Python code. One implementation detail though: as we are multiplying probabilities, we might end up with very very small probabilities as we go further. We apply logarithms to them and calculate log probabilities, so that we are not dealing with extreme values.
The prev key gives the state of her in the previous day. As we don’t have the previous day on the first day, we write it as None.
Beyond the first day
Now, we do the same thing for the other days. So, we employ a loop from the second day to the last day. For each day, we append a dictionary. The dictionary of the particular day has all the states as the key and probabilities associated with all the states as the value. It has one key-value pair given by prev key which gives the previous day state. The prev key would be useful for calculating the compound probabilities (log probabilities in our case).
Let’s take an instance of the second day, and understand the algorithm.
We know her state of the first day by iterating over all the states on the first day and finding which state has the maximum log probability. We save the state in the prev key. Then, we go on to calculate the compound log probabilities of all the states on the second day. For doing that we make use of the transition and emission probabilities. We saw, in our example, she is sad on the first day. So, for calculating the probability that she is happy on the second day (given that she gave laugh emoji), we first calculate the product of the probability of her transitioning from sad state to happy state and the probability of her laughing if she is happy. The first probability, we would get from the transition probability matrix, and the second probability, we would get from the emission probability matrix. In our case, the first probability, the probability that she would transition from sad state to happy state, is given by transition_p[‘sad’][‘happy’], and the second probability, the probability that she laughs if she is happy, is given by emission_p[‘happy’][‘laugh’]. The product is then multiplied with the previous day's highest probability (probability of being sad in our case which had a value of 0.15), and we will get the probability of coming to the current state on the second day. The process is continued to the last day, and we would have her states for all the days.
Let’s run the code and see what are the (log) probabilities we end up with.

So, we see the logprobabilities list, which gives (log) probabilities of all the states. The state of the first day can be found from value at the prev key of the second element. Here, the states of the first, second, third and fourth day are sad, happy, happy, and sad respectively. The state of the last (fifth) day can be found by seeing which state has the highest log probability in the last element of the list. As we can see ‘happy’ state has the highest log probability, she was happy on the last day.
Out of five days, she was happy for three days and sad for two days. Better than her initial probabilities, so I am happy with her states ;)
Applications
What we used here is the Viterbi algorithm. The algorithm is a dynamic programming algorithm for finding the most likely sequence of hidden states. The sequence of hidden states is called Viterbi path. Using the algorithm to find spouse’s state is fun. Why don’t you too try with your spouse or BF or GF or best friend or any friend?
The algorithm can be used in many other applications too. In school days, I was asked a question in Nepali examination to find part of speech in a sentence — पदवर्ग छुट्याउ. That can be done using the Viterbi algorithm too — POS tagging. Other applications include speech recognition, speech synthesis, computational linguistics, and many more.
More stuff on algorithms coming soon, stay tuned! In the meantime, please let me know your thoughts on this article in the comment section. Stay safe, stay healthy. :)
